
Captain’s log
Star date 71750.51. Our mission is to use R statistical software to extract star dates mentioned in the captain’s log from the scripts of Star Trek: The Next Generation and observe their progression over the course of the show’s seven seasons. There appears to be some mismatch in the frequency of digits after the decimal point – could this indicate poor ability to choose random numbers? Or something more sinister? We shall venture deep into uncharted territory for answers…
We’re going to:
- iterate reading in text files – containing ‘Star Trek: The Next Generation’ (ST:TNG) scripts – to R and then extract stardates using the {purrr} and {stringr} packages
- web scrape episode names using the {rvest} package and join them to the stardates data
- tabulate and plot these interactively with {ggplot2}, {plotly} and {DT}
There’s probably nothing new here for real Star Trek fans, but you might learn something new if you’re an R fan.
⚠️ Also, very minor spoiler alert for a couple of ST:TNG episodes. ⚠️
Lieutenant Commander Data
First, you can download the ST:TNG scripts from the Star Trek Minutiae website. These are provided in a zipped folder with 176 text files – one for each episode.
Number One
Now we’re going to extract the content of the the text files using the read_lines() function from the {readr} package. We’ll iterate over each file with the map() function from the {purrr} package to read them into a list object where each element is a script.
library(purrr) # iterate functions over files
library(readr) # for reading files
# Path to where I've put the scripts
# (change this to where they are on your machine)
path <- "../../static/datasets/tng_scripts/"
scripts <- map(
list.files( # create vector of filepath strings to each file
path, # filepath to where downloaded script files are
full.names = TRUE # full filepath
),
read_lines # read the content from each filepath
)We can take a look at some example lines from the title page of the first script.
scripts[[1]][17:24]## [1] " STAR TREK: THE NEXT GENERATION "
## [2] " "
## [3] " \"Encounter at Farpoint\" "
## [4] " "
## [5] " by "
## [6] " D.C. Fontana "
## [7] " and "
## [8] " Gene Roddenberry "Our first example of a star date is in the Captain’s log voiceover in line 47 of the first script. (The \t denotes tab space.)
scripts[[1]][46:47]## [1] "\t\t\t\t\tPICARD V.O."
## [2] "\t\t\tCaptain's log, stardate 42353.7."Engage!
We want to extract stardate strings from each script. As you can see from Picard’s voiceover (above), these are given in the form ‘XXXXX.X’, where each X is a digit.
We can extract these with str_extract_all() from the stringr package, using a regex (regular expression).
Our regex is written date[:space:][[:digit:]\\.[:digit:]]{7}. This means:
- find a string that starts with the word date and is followed by a space (i.e.
date) - which is followed by a string that contains digits (
[:digit:]) with a period (\\.) inside - with a total length of seven characters (
{7})’
This creates a list object with an element for each script that contains all the regex-matched strings.
library(stringr) # manipulate strings
stardate_extract <- str_extract_all( # extract all instances
string = scripts, # object to extract from
pattern = "date[:space:][[:digit:]\\.[:digit:]]{7}" # regex
)
stardate_extract[1:3] # see the first few list elements## [[1]]
## [1] "date 42353.7" "date 42354.1" "date 42354.2" "date 42354.7" "date 42372.5"
##
## [[2]]
## [1] "date 41209.2" "date 41209.3"
##
## [[3]]
## [1] "date 41235.2" "date 41235.3"We’re now going to make the data into a tidy dataframe and clean it up so it’s easier to work with.
library(dplyr) # data manipulation and pipe operator (%>%)
library(tibble) # tidy tables
library(tidyr) # tidying dataframes
stardate_tidy <- stardate_extract %>%
enframe() %>% # list to dataframe (one row per episode)
unnest() %>% # dataframe with one row per stardate
transmute( # create columns and retain only these
episode = name, # rename
stardate = str_replace( # replace specified strings
string = value,
pattern = "date ", # find this string
replacement = "" # replace with blank so we only have digits left
)
) %>%
mutate( # create new columns
# manually apply season number to each episode
season = as.character(
case_when(
episode %in% 1:25 ~ "1",
episode %in% 26:47 ~ "2",
episode %in% 48:73 ~ "3",
episode %in% 74:99 ~ "4",
episode %in% 100:125 ~ "5",
episode %in% 126:151 ~ "6",
episode %in% 152:176 ~ "7"
)
),
# replace strings not in the form XXXXX.X
stardate = as.numeric(
if_else(
condition = stardate %in% c("41148..", "40052..", "37650.."),
true = "NA", # fill column with NA if true
false = stardate # otherwise supply the stardate
)
),
# extract the digit after the decimal place in the stardate
stardate_decimal = as.numeric(
str_sub(as.character(stardate), 7, 7)
),
# if no digit after decimal, give it zero
stardate_decimal = if_else(
condition = is.na(stardate_decimal),
true = 0,
false = stardate_decimal
)
) %>%
filter(!is.na(stardate)) # remove NAs
glimpse(stardate_tidy) # take a look## Observations: 263
## Variables: 4
## $ episode <int> 1, 1, 1, 1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 5, 5, 6, 6, 7…
## $ stardate <dbl> 42353.7, 42354.1, 42354.2, 42354.7, 42372.5, 41209.2…
## $ season <chr> "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1…
## $ stardate_decimal <dbl> 7, 1, 2, 7, 5, 2, 3, 2, 3, 5, 7, 1, 2, 3, 4, 6, 8, 3…Prepare a scanner probe
We could extract episode names from the scripts, but another option is to scrape them from the ST:TNG episode guide on Wikipedia.
If you visit that link, you’ll notice that the tables of episodes actually give a stardate, but they only provide one per episode – our script-scraping shows that many episodes have multiple instances of stardates.
We can use the rvest package by Hadley Wickham to perform the scrape. This works by supplying a website address and the path of the thing we want to extract – the episode name column of tables on the Wikipedia page. I used SelectorGadget – a point-and-click tool for finding the CSS selectors for elements of webpages – for this column in each of the tables on the Wikipedia page (.wikiepisodetable tr > :nth-child(3)). A short how-to vignette is available for {rvest} + SelectorGadget.
library(rvest)
# store website address
tng_ep_wiki <- read_html(
"https://en.wikipedia.org/wiki/List_of_Star_Trek:_The_Next_Generation_episodes"
)
# extract and tidy
tng_ep_names <- tng_ep_wiki %>% # website address
html_nodes(".wikiepisodetable tr > :nth-child(3)") %>% # via SelectorGadget
html_text() %>% # extract text
tibble() %>% # to dataframe
rename(episode_title = ".") %>% # sensible column name
filter(episode_title != "Title") %>% # remove table headers
mutate(episode = row_number()) # episode number (join key)
print(tng_ep_names)## # A tibble: 176 x 2
## episode_title episode
## <chr> <int>
## 1 "\"Encounter at Farpoint\"" 1
## 2 "\"The Naked Now\"" 2
## 3 "\"Code of Honor\"" 3
## 4 "\"The Last Outpost\"" 4
## 5 "\"Where No One Has Gone Before\"" 5
## 6 "\"Lonely Among Us\"" 6
## 7 "\"Justice\"" 7
## 8 "\"The Battle\"" 8
## 9 "\"Hide and Q\"" 9
## 10 "\"Haven\"" 10
## # … with 166 more rowsSo now we can join the episode names to the dataframe generated from the scripts. This gives us a table with a row per stardate extracted, with its associated season, episode number and episode name.
stardate_tidy_names <- left_join(
x = stardate_tidy, # to this dataframe
y = tng_ep_names, # join these data
by = "episode" # join key
) %>%
select(season, episode, episode_title, stardate, stardate_decimal)We can make these data into an interactive table with the DT::datatable() htmlwidget. The output table can be searched (search box in upper right) and filtered (filters under each column).
library(DT)
stardate_tidy_names %>%
# factors get a dropdown filter, character strings don't
mutate(
season = as.factor(season),
episode_title = as.factor(episode_title)
) %>%
datatable(
caption = "Stardates found in ST:TNG scripts",
filter = "top", # where to put filter boxes
rownames = FALSE, # row numbers not needed
options = list(
pageLength = 5, # show 5 rows at a time
autoWidth = TRUE
)
)So that’s a searchable list of all the stardates in each episode.
On screen
Let’s visualise the stardates by episode.
We can make this interactive using the {plotly} package – another htmlwidget for R – that conveniently has the function ggplotly() that can turn a ggplot object into an interactive plot. You can hover over each point to find out more information about it.
Obviously there’s a package (ggsci) that contains a discrete colour scale based on the shirts of the Enterprise crew. Obviously we’ll use that here.
library(ggplot2) # basic plotting
library(plotly) # make plot interactive
library(ggsci) # star trek colour scale
library(ggthemes) # dark plot theme
# create basic plot
stardate_dotplot <- stardate_tidy_names %>%
ggplot() +
geom_point( # dotplot
aes(
x = episode,
y = stardate,
color = season, # each colour gets own colour
label = episode_title
)
) +
labs(title = "Stardates are almost (but not quite) chronological") +
theme_solarized_2(light = FALSE) + # dark background
scale_color_startrek() # Star Trek uniform coloursWe can make this interactive with {plotly`} You can hover over the points to see details in a tooltip and use the Plotly tools that appear on hover in the top-right to zoom, download, etc.
# make plot interactive
stardate_dotplot %>%
ggplotly() %>%
layout(margin = list(l = 75)) # adjust margin to fit y-axis labelSo there were some non-chronological stardates between episodes of the first and second series and at the beginning of the third, but the stardate-episode relationship became more linear after that.
Three points seem to be anomalous with stardates well before the present time period of the episode. Without spoiling them (too much), we can see that each of these episodes takes place in, or references, the past.
‘Identity Crisis’ (season 4, episode 91, stardate 40164.7) takes place partly in the past:
scripts[[91]][127:129]## [1] "\tGEORDI moves into view, holding a Tricorder. (Note:"
## [2] "\tGeordi is younger here, wearing a slightly different,"
## [3] "\tearlier version of his VISOR.)"‘Dark Page’ (season 7, episode 158, stardate 30620.1) has a scene involving a diary:
scripts[[158]][c(2221:2224, 2233:2235)]## [1] "\t\t\t\t\tTROI"
## [2] "\t\t\tThere's a lot to review. My"
## [3] "\t\t\tmother's kept a journal since she"
## [4] "\t\t\twas first married..."
## [5] "\t\t\t\t\tPICARD"
## [6] "\t\t\tThe first entry seems to be"
## [7] "\t\t\tStardate 30620.1."‘All Good Things’ (season 7, episode 176, stardate 41153.7) involves some time travel for Captain Picard:
scripts[[176]][1561:1569]## [1] "\t\t\t\t\tPICARD (V.O.)"
## [2] "\t\t\tPersonal Log: Stardate 41153.7."
## [3] "\t\t\tRecorded under security lockout"
## [4] "\t\t\tOmega three-two-seven. I have"
## [5] "\t\t\tdecided not to inform this crew of"
## [6] "\t\t\tmy experiences. If it's true that"
## [7] "\t\t\tI've travelled to the past, I"
## [8] "\t\t\tcannot risk giving them"
## [9] "\t\t\tforeknowledge of what's to come."Enhance!
So we’ve had a look at the stadates over the course of ST:TNG, but our other goal was to investigate those digits after the decimal place. Adriana pointed out that there appear to be very few zeroes and wondered how random the distribution of these digits could be.
Let’s take a look at a barplot of the frequency of the digit after the decimal place.
stardate_tidy_names %>%
ggplot() +
geom_bar(aes(as.character(stardate_decimal)), fill = "#CC0C00FF") +
labs(
title = "Decimals one to three are most frequent and zero the least frequent",
x = "stardate decimal value"
) +
theme_solarized_2(light = FALSE)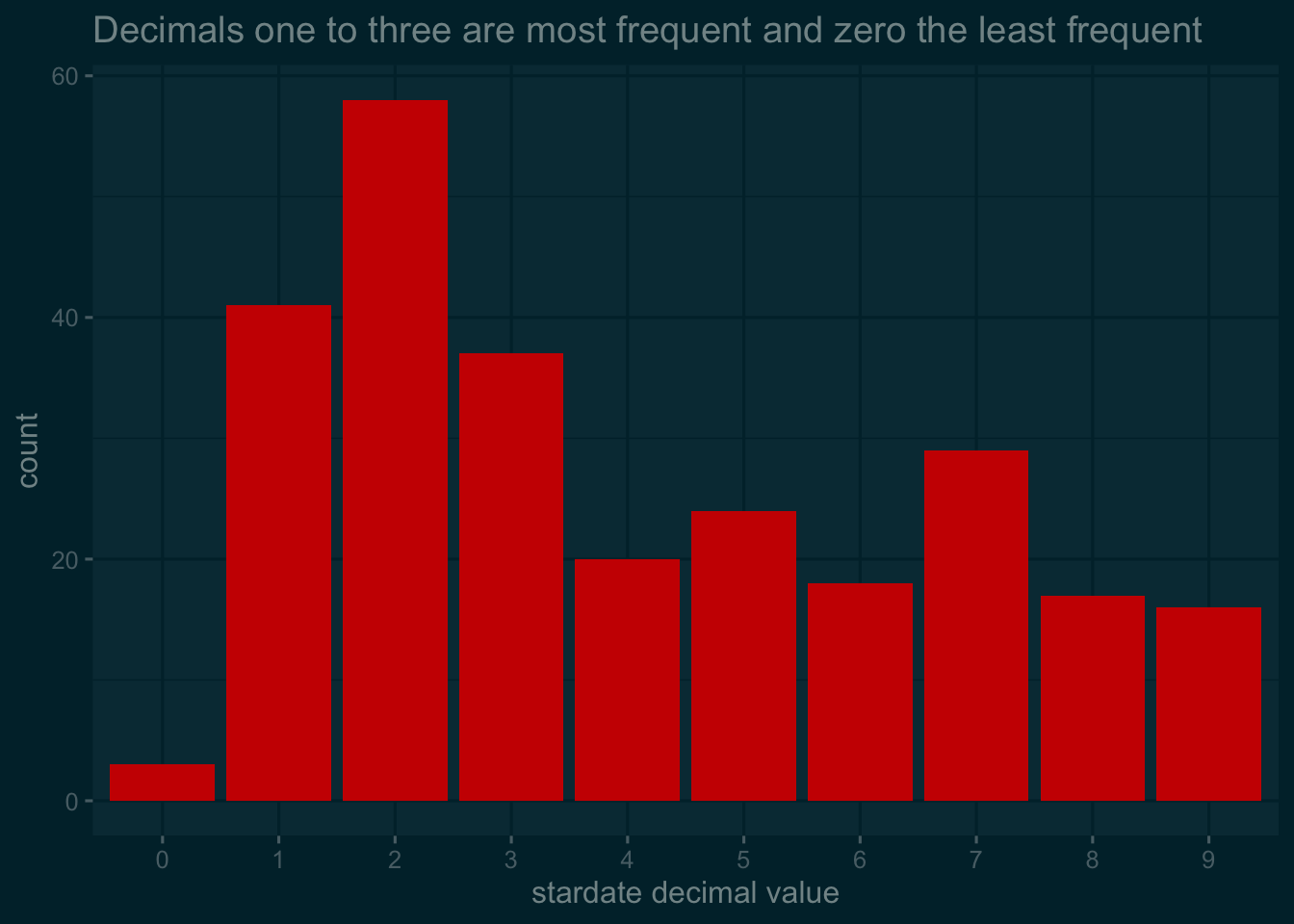
Hm. Few zeroes – almost none – as suspected. The most common is 2, followed by 1 and 3. There’s some similarity in frequency of the other digits, with 7 most frequent of those (everyone’s favourite ‘random’ number).
Belay that
How does this pattern look across the seasons?
stardate_tidy_names %>%
ggplot() +
geom_bar(
aes(as.character(stardate_decimal)),
fill= c(
rep("#CC0C00FF", 10),
rep("#5C88DAFF", 9),
rep("#84BD00FF", 10),
rep("#FFCD00FF", 9),
rep("#7C878EFF", 10),
rep("#00B5E2FF", 8),
rep("#00AF66FF", 8)
)
) +
labs(
title = "There's a similar(ish) pattern of decimal stardate frequency\nacross seasons",
x = "stardate decimal value"
) +
facet_wrap(~ season) +
theme_solarized_2(light = FALSE)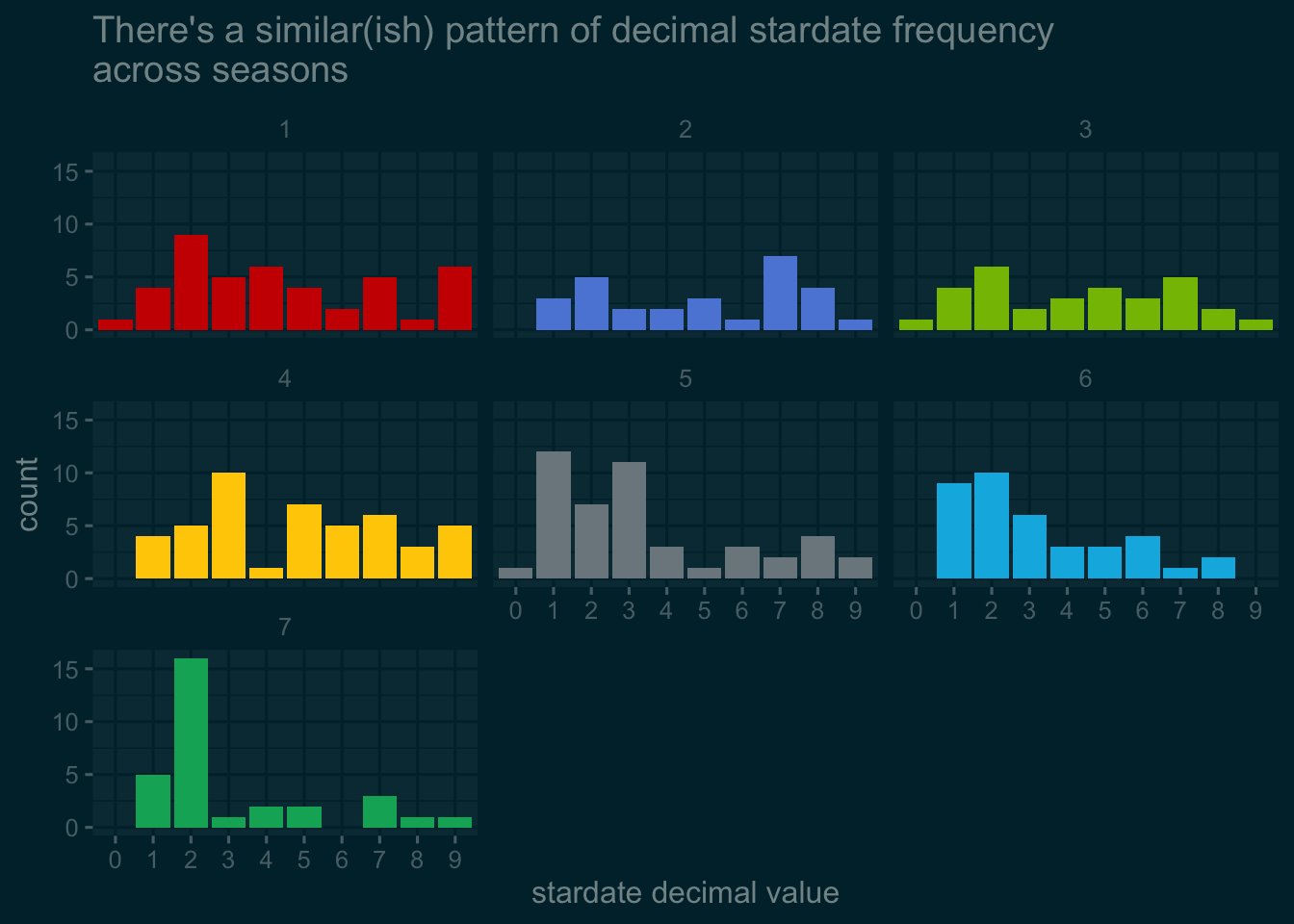
Still few (or no) zeroes. Digits 1 to 3 generally popular. Not totally consistent.
Speculate
So stardates are more or less chronological across the duration of ST:TNG’s seven series, implying that the writers had a system in place. A few wobbles in consistency appear during the first few season suggest that it took some time to get this right. None of this is new information (see the links in the Open Channel! section below).
It seems the vast majority of episodes take place in the programme’s present with a few exceptions. We may have missed some forays through time simply because the stardate was unknown or unmentioned.
There appears to be some non-random pattern in the frequency of the digits 0 to 9 after the decimal place. It’s not entirely clear if there is a reason for this within the universe of ST:TNG, but perhaps the writers put little thought to it and humans are bad at selecting random numbers anyway (relevant xkcd).
It turns out that this kind of investigation has been done before, buried in Section II.5 of STArchive’s stardate FAQ. I don’t know what method was used, but the exact results differ to the ones presented here. The basic pattern is similar though: few zeroes with 1, 2 and 3 being most common.
Open channel
Only too late did I realise that there is an RTrek GitHub organisation with a Star Trek package, TNG datasets and some other functions.
A selection of further reading:
- ‘Memory Alpha is a collaborative project to create the most definitive, accurate, and accessible encyclopedia and reference for everything related to Star Trek’, including stardates
- ‘The STArchive is home to the… Ships and Locations lists… [and] a few other technical FAQs’, including a deep-dive into the theories in a Stardates in Star Trek FAQ
- Trekguide’s take on the messiness of stardates also includes a stardate converter
- There’s a handy universal stardate converter at Redirected Insanity
- The scripts were downloaded from Star Trek Minutiae, a site that has ‘obscure references and little-known facts’ and ‘explore[s] and expand[s] the wondrous multiverse of Star Trek’
- A simpler guide to stardates can be found on Mentalfloss
- You can find the full list of The Next Generation episodes on Wikipedia
Full stop!

Session info
## [1] "Last updated 2020-02-10"## ─ Session info ───────────────────────────────────────────────────────────────
## setting value
## version R version 3.6.0 (2019-04-26)
## os macOS Mojave 10.14.6
## system x86_64, darwin15.6.0
## ui X11
## language (EN)
## collate en_GB.UTF-8
## ctype en_GB.UTF-8
## tz Europe/London
## date 2020-02-10
##
## ─ Packages ───────────────────────────────────────────────────────────────────
## package * version date lib source
## assertthat 0.2.1 2019-03-21 [1] CRAN (R 3.6.0)
## blogdown 0.12 2019-05-01 [1] CRAN (R 3.6.0)
## bookdown 0.10 2019-05-10 [1] CRAN (R 3.6.0)
## cli 2.0.1 2020-01-08 [1] CRAN (R 3.6.0)
## colorspace 1.4-1 2019-03-18 [1] CRAN (R 3.6.0)
## crayon 1.3.4 2017-09-16 [1] CRAN (R 3.6.0)
## crosstalk 1.0.0 2016-12-21 [1] CRAN (R 3.6.0)
## curl 4.3 2019-12-02 [1] CRAN (R 3.6.0)
## data.table 1.12.6 2019-10-18 [1] CRAN (R 3.6.0)
## digest 0.6.23 2019-11-23 [1] CRAN (R 3.6.0)
## dplyr * 0.8.3 2019-07-04 [1] CRAN (R 3.6.0)
## DT * 0.11 2019-12-19 [1] CRAN (R 3.6.0)
## emo * 0.0.0.9000 2020-01-21 [1] Github (hadley/emo@3f03b11)
## evaluate 0.14 2019-05-28 [1] CRAN (R 3.6.0)
## fansi 0.4.1 2020-01-08 [1] CRAN (R 3.6.0)
## farver 2.0.1 2019-11-13 [1] CRAN (R 3.6.0)
## fastmap 1.0.1 2019-10-08 [1] CRAN (R 3.6.0)
## ggplot2 * 3.2.1 2019-08-10 [1] CRAN (R 3.6.0)
## ggsci * 2.9 2018-05-14 [1] CRAN (R 3.6.0)
## ggthemes * 4.2.0 2019-05-13 [1] CRAN (R 3.6.0)
## glue 1.3.1 2019-03-12 [1] CRAN (R 3.6.0)
## gtable 0.3.0 2019-03-25 [1] CRAN (R 3.6.0)
## hms 0.5.1 2019-08-23 [1] CRAN (R 3.6.0)
## htmltools 0.4.0 2019-10-04 [1] CRAN (R 3.6.0)
## htmlwidgets 1.5.1 2019-10-08 [1] CRAN (R 3.6.0)
## httpuv 1.5.2 2019-09-11 [1] CRAN (R 3.6.0)
## httr 1.4.1 2019-08-05 [1] CRAN (R 3.6.0)
## jsonlite 1.6.1 2020-02-02 [1] CRAN (R 3.6.0)
## knitr 1.26 2019-11-12 [1] CRAN (R 3.6.0)
## labeling 0.3 2014-08-23 [1] CRAN (R 3.6.0)
## later 1.0.0 2019-10-04 [1] CRAN (R 3.6.0)
## lazyeval 0.2.2 2019-03-15 [1] CRAN (R 3.6.0)
## lifecycle 0.1.0 2019-08-01 [1] CRAN (R 3.6.0)
## lubridate 1.7.4 2018-04-11 [1] CRAN (R 3.6.0)
## magrittr 1.5 2014-11-22 [1] CRAN (R 3.6.0)
## mime 0.9 2020-02-04 [1] CRAN (R 3.6.0)
## munsell 0.5.0 2018-06-12 [1] CRAN (R 3.6.0)
## pillar 1.4.3 2019-12-20 [1] CRAN (R 3.6.0)
## pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 3.6.0)
## plotly * 4.9.1 2019-11-07 [1] CRAN (R 3.6.0)
## promises 1.1.0 2019-10-04 [1] CRAN (R 3.6.0)
## purrr * 0.3.3 2019-10-18 [1] CRAN (R 3.6.0)
## R6 2.4.1 2019-11-12 [1] CRAN (R 3.6.0)
## Rcpp 1.0.3 2019-11-08 [1] CRAN (R 3.6.0)
## readr * 1.3.1 2018-12-21 [1] CRAN (R 3.6.0)
## rlang 0.4.4 2020-01-28 [1] CRAN (R 3.6.0)
## rmarkdown 2.0 2019-12-12 [1] CRAN (R 3.6.0)
## rvest * 0.3.5 2019-11-08 [1] CRAN (R 3.6.0)
## scales 1.1.0 2019-11-18 [1] CRAN (R 3.6.0)
## selectr 0.4-2 2019-11-20 [1] CRAN (R 3.6.0)
## sessioninfo 1.1.1 2018-11-05 [1] CRAN (R 3.6.0)
## shiny 1.4.0 2019-10-10 [1] CRAN (R 3.6.0)
## stringi 1.4.5 2020-01-11 [1] CRAN (R 3.6.0)
## stringr * 1.4.0 2019-02-10 [1] CRAN (R 3.6.0)
## tibble * 2.1.3 2019-06-06 [1] CRAN (R 3.6.0)
## tidyr * 1.0.0 2019-09-11 [1] CRAN (R 3.6.0)
## tidyselect 0.2.5 2018-10-11 [1] CRAN (R 3.6.0)
## utf8 1.1.4 2018-05-24 [1] CRAN (R 3.6.0)
## vctrs 0.2.2 2020-01-24 [1] CRAN (R 3.6.0)
## viridisLite 0.3.0 2018-02-01 [1] CRAN (R 3.6.0)
## withr 2.1.2 2018-03-15 [1] CRAN (R 3.6.0)
## xfun 0.11 2019-11-12 [1] CRAN (R 3.6.0)
## xml2 * 1.2.2 2019-08-09 [1] CRAN (R 3.6.0)
## xtable 1.8-4 2019-04-21 [1] CRAN (R 3.6.0)
## yaml 2.2.1 2020-02-01 [1] CRAN (R 3.6.0)
##
## [1] /Library/Frameworks/R.framework/Versions/3.6/Resources/libraryThe star date for today’s date (14 April 2018) as calculated using the trekguide.com method; this ‘would be the stardate of this week’s episode if The Next Generation and its spinoffs were still in production’.↩